[libvirt] [RFC] Reporting host interface status/statistics via netcf/libvirt, and listing active vs. inactive interfaces

I've already been working on incorporating physical host interface configuration into libvirt by way of using libnetcf on the backend. It's becoming apparent that, in addition to modifying and reporting the current configuration of interfaces, libvirt users also want to query current status of each interface (up/down, possibly other flags, packet/byte/error counts, current IP address, etc). There are two possible ways of doing this: 1) maintain libnetcf's focus on just interface configuration, and add code directly into libvirt to grab this information via appropriate ioctls or 2) add the functionality to libnetcf, and have libvirt call the new libnetcf API. (2) seems to make the most sense, because likely other libnetcf consumers will want this capability too. I'm thinking of a single API, something like: int netcf_if_status(netcf_if *, netcf_if_stats *); (or maybe int netcf_if_info(netcf_if *, netcf_if_info *)) I haven't really put much thought into the details of what should be in netcf_if_stats yet (beyond what I listed above), but wanted to get this idea out there so people can start sounding off (if I'm going down the wrong road, I'd rather be put on the right path before I get too far along!) This function could be exposed in the libvirt API as something like: int virInterfaceStatus|Info(virInterffacePtr iface, virInterfaceStats|Info *info); Any comments/ideas on this? (One possible complication I can see is interfaces with multiple associated IPs. On some platforms, each interface can have only a single IPv4 and a single IPv6 address (more IPs == more interfaces), but on others there can be multiples.) A (kind of) separate issue: In libvirt we want to be able to list active (up) and inactive (down) interfaces separately. For consistency, libvirt's way of exposing that will be to mimic what is done with virConnectListNetworks() (active) vs. virConnectListDefinedNetworks() (inactive). But netcf could do it with an extra argument to ncf_list_interfaces(). If the latter, should the default behavior be to list all interfaces, with flags set to eliminate up or down interfaces? 0 (list all) NETCF_NOLIST_UP NETCF_NOLIST_DOWN Or should the values be something like this: 0 (list all) NETCF_LIST_UP_ONLY NETCF_LIST_DOWN_ONLY (UP_ONLY + DOWN_ONLY would be equivalent to 0. As long as nobody came up with a good reason for "0". So should we do one of those, or should we mimic libirt's virNetwork API in libnetcf too?

On Tue, 2009-06-16 at 15:12 -0400, Laine Stump wrote:
I've already been working on incorporating physical host interface configuration into libvirt by way of using libnetcf on the backend. It's becoming apparent that, in addition to modifying and reporting the current configuration of interfaces, libvirt users also want to query current status of each interface (up/down, possibly other flags, packet/byte/error counts, current IP address, etc).
There are two possible ways of doing this:
1) maintain libnetcf's focus on just interface configuration, and add code directly into libvirt to grab this information via appropriate ioctls
or
2) add the functionality to libnetcf, and have libvirt call the new libnetcf API.
(2) seems to make the most sense, because likely other libnetcf consumers will want this capability too.
I agree that netcf is the right place for this functionality; the downside either way is that we'll wind up reimplementing a good bit of ifconfig's functionality. But seeing how net-tools does not expose a library that's inevitable (and it's mostly an exercise in calling ioctl anyway).
I'm thinking of a single API, something like:
int netcf_if_status(netcf_if *, netcf_if_stats *);
(or maybe int netcf_if_info(netcf_if *, netcf_if_info *))
I haven't really put much thought into the details of what should be in netcf_if_stats yet (beyond what I listed above), but wanted to get this idea out there so people can start sounding off (if I'm going down the wrong road, I'd rather be put on the right path before I get too far along!)
There should really be multiple API's to cover the functionality; rolling it all into one giant struct seems too inflexible. I am thinking there should be at least 3 calls * int netcf_if_operstate(netcf_if *) - return 1 if interface is up, 0 if not * int netcf_if_stats(netcf_if *, netcf_if_stats *) - get rx/tx statistics; which ones needs to be figured out in detail * int netcf_if_addrinfo(netcf_if *, netcf_if_addrinfo *) - get address info, i.e. IPv4 and/or IPv6 addresses assigned to the interface One wrinkle is that netcf operates at the level of 'connections', not with individual interfaces, e.g. when a physical NIC eth0 is enslaved to a bridge br0, only the bridge is currently visible through the netcf API. So for statistics gathering, you'd only see the statistics for br0 - if statistics for individual devices on the bridge are needed, we can either report all of them in netcf_if_stats, or provide a mechanism to get at the subinterfaces so that netcf_if_stats etc. can be called separately for br0 and eth0.
But netcf could do it with an extra argument to ncf_list_interfaces(). If the latter, should the default behavior be to list all interfaces, with flags set to eliminate up or down interfaces?
0 (list all) NETCF_NOLIST_UP NETCF_NOLIST_DOWN
Or should the values be something like this:
0 (list all) NETCF_LIST_UP_ONLY NETCF_LIST_DOWN_ONLY
(UP_ONLY + DOWN_ONLY would be equivalent to 0. As long as nobody came up with a good reason for "0".
So should we do one of those, or should we mimic libirt's virNetwork API in libnetcf too?
I'd lean towards the flag approach, but without the special meaning for 0 - if you specify any flags, you won't get any interfaces ;) Since we're dealing with compound interfaces, we also need to define what it means for a bridge to be up - e.g., the bridge device and all enslaved physical NICs need to be up. David

On Wed, Jun 17, 2009 at 11:16:28AM -0700, David Lutterkort wrote:
* int netcf_if_operstate(netcf_if *) - return 1 if interface is up, 0 if not * int netcf_if_stats(netcf_if *, netcf_if_stats *) - get rx/tx statistics; which ones needs to be figured out in detail * int netcf_if_addrinfo(netcf_if *, netcf_if_addrinfo *) - get address info, i.e. IPv4 and/or IPv6 addresses assigned to the interface
One wrinkle is that netcf operates at the level of 'connections', not with individual interfaces, e.g. when a physical NIC eth0 is enslaved to a bridge br0, only the bridge is currently visible through the netcf API. So for statistics gathering, you'd only see the statistics for br0 - if statistics for individual devices on the bridge are needed, we can either report all of them in netcf_if_stats, or provide a mechanism to get at the subinterfaces so that netcf_if_stats etc. can be called separately for br0 and eth0.
Hmm, this seems wrong to me. 'connections' are an application level concept. The libvirt API should be exposing all the interfaces on the host, so you should see all the br0, bond0, and eth0 & eth1 devices for a bridge on top of a bond. An application using libvirt can filter this to only show the logical 'connections' if required. If you start out with a fresh machine and virConnectListInterfaces gives you back 2 objects for 'eth0' and 'eth1', I would not expect these objects to disappear from the API when I created a 'bond0' out of them. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Wed, 2009-06-17 at 19:27 +0100, Daniel P. Berrange wrote:
Hmm, this seems wrong to me. 'connections' are an application level concept. The libvirt API should be exposing all the interfaces on the host, so you should see all the br0, bond0, and eth0 & eth1 devices for a bridge on top of a bond. An application using libvirt can filter this to only show the logical 'connections' if required.
If you start out with a fresh machine and virConnectListInterfaces gives you back 2 objects for 'eth0' and 'eth1', I would not expect these objects to disappear from the API when I created a 'bond0' out of them.
We probably need two different views of the network setup: one that considers network devices (and in that area, you would always see eth0, eth1 etc. even when they are enslaved to bridges/bonds) and one that considers connections; on some OS's, it doesn't make sense to talk about eth0 when it's enslaved to a bridge br0 for config purposes. [1] has an example of how a bridge is configured on Debian - note that eth0 should not be mentioned anymore outside of the br0 setup. Of course, eth0 is still around as an interface/device, and, at a minimum, has statistics that are different from the bridge's statistics.
From the netcf side, we should probably restructure the model to talk about connections (roughly what netcf_if is today, maybe renamed to netcf_conn) and interfaces/devices, and a way to get the devices from a connection, so that you can list all the interfaces involved in a bridge (connection)
David [1] http://compsoc.dur.ac.uk/~djw/qemu.html
On Wed, Jun 17, 2009 at 07:27:43PM +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 11:16:28AM -0700, David Lutterkort wrote:
* int netcf_if_operstate(netcf_if *) - return 1 if interface is up, 0 if not * int netcf_if_stats(netcf_if *, netcf_if_stats *) - get rx/tx statistics; which ones needs to be figured out in detail * int netcf_if_addrinfo(netcf_if *, netcf_if_addrinfo *) - get address info, i.e. IPv4 and/or IPv6 addresses assigned to the interface
One wrinkle is that netcf operates at the level of 'connections', not with individual interfaces, e.g. when a physical NIC eth0 is enslaved to a bridge br0, only the bridge is currently visible through the netcf API. So for statistics gathering, you'd only see the statistics for br0 - if statistics for individual devices on the bridge are needed, we can either report all of them in netcf_if_stats, or provide a mechanism to get at the subinterfaces so that netcf_if_stats etc. can be called separately for br0 and eth0.
Hmm, this seems wrong to me. 'connections' are an application level concept. The libvirt API should be exposing all the interfaces on the host, so you should see all the br0, bond0, and eth0 & eth1 devices for a bridge on top of a bond. An application using libvirt can filter this to only show the logical 'connections' if required.
If you start out with a fresh machine and virConnectListInterfaces gives you back 2 objects for 'eth0' and 'eth1', I would not expect these objects to disappear from the API when I created a 'bond0' out of them.
Actually I'm going to possibly disagree with myself now :-) I was mixing up the concept of physical interfaces vs logical interfaces. Our node device APIs already provide the ability to enumerate all physical interfaces, so there's no need to dup that in the inteface APIs. So yes the virInterface APIs only need to show the logical configured interfaces, eg just the br0 and not the eth0 underneath it. The statistics would be reported wrt the br0 device - AFAICT there's no need to report statistics wrt to the underlying eth0 device - at least not in the context of virt-management. For general non-virt host management you might care about underling eth0 devices eg to see how a bond device is working, but that could be out of scope of libvirt and the job of a general OS monitoring app Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Tue, Jun 16, 2009 at 03:12:36PM -0400, Laine Stump wrote:
I've already been working on incorporating physical host interface configuration into libvirt by way of using libnetcf on the backend. It's becoming apparent that, in addition to modifying and reporting the current configuration of interfaces, libvirt users also want to query current status of each interface (up/down, possibly other flags, packet/byte/error counts, current IP address, etc).
This function could be exposed in the libvirt API as something like:
int virInterfaceStatus|Info(virInterffacePtr iface, virInterfaceStats|Info *info);
That is reasonable.
Any comments/ideas on this?
(One possible complication I can see is interfaces with multiple associated IPs. On some platforms, each interface can have only a single IPv4 and a single IPv6 address (more IPs == more interfaces), but on others there can be multiples.)
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ? Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote:
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured. David

On Wed, Jun 17, 2009 at 12:22:13PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote:
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured.
BTW I was looking at the Relax-NG grammar and found the following confusing when providing an IP address: <element name="ip"> <optional> <attribute name="address"><ref name="ip-mask"/></attribute> </optional> </element> I'm not really sure what ip-mask really means, are you trying to put in a single attribute both the IP address and the netmask ? If that's the case I would really suggest to split the two as separated IP and netmask in the XML structure, either separate attributes or another element for the netmask. Best to us the explicit structure of XML than a construct hidden inside the text field, unless I misunderstood the use case... Sorry for hijacking :-) Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Wed, Jun 17, 2009 at 09:42:11PM +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 12:22:13PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote:
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured.
BTW I was looking at the Relax-NG grammar and found the following confusing when providing an IP address:
<element name="ip"> <optional> <attribute name="address"><ref name="ip-mask"/></attribute> </optional> </element>
I'm not really sure what ip-mask really means, are you trying to put in a single attribute both the IP address and the netmask ? If that's the case I would really suggest to split the two as separated IP and netmask in the XML structure, either separate attributes or another element for the netmask. Best to us the explicit structure of XML than a construct hidden inside the text field, unless I misunderstood the use case...
'netmask' should really be avoided these days, in preference to 'prefix' since the latter works for IPv4 and IPv6, while the former only works for IPv4. 'netmask' can be auto-calculated from 'prefix' by apps if they really care about it. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Wed, Jun 17, 2009 at 09:03:32PM +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 09:42:11PM +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 12:22:13PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote:
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured.
BTW I was looking at the Relax-NG grammar and found the following confusing when providing an IP address:
<element name="ip"> <optional> <attribute name="address"><ref name="ip-mask"/></attribute> </optional> </element>
I'm not really sure what ip-mask really means, are you trying to put in a single attribute both the IP address and the netmask ? If that's the case I would really suggest to split the two as separated IP and netmask in the XML structure, either separate attributes or another element for the netmask. Best to us the explicit structure of XML than a construct hidden inside the text field, unless I misunderstood the use case...
'netmask' should really be avoided these days, in preference to 'prefix' since the latter works for IPv4 and IPv6, while the former only works for IPv4. 'netmask' can be auto-calculated from 'prefix' by apps if they really care about it.
Fine by me, just that I think they should be hold by 2 separate attributes or element if possible at this point. Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Wed, 2009-06-17 at 22:10 +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 09:03:32PM +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 09:42:11PM +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 12:22:13PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote:
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured.
BTW I was looking at the Relax-NG grammar and found the following confusing when providing an IP address:
<element name="ip"> <optional> <attribute name="address"><ref name="ip-mask"/></attribute> </optional> </element>
I'm not really sure what ip-mask really means, are you trying to put in a single attribute both the IP address and the netmask ? If that's the case I would really suggest to split the two as separated IP and netmask in the XML structure, either separate attributes or another element for the netmask. Best to us the explicit structure of XML than a construct hidden inside the text field, unless I misunderstood the use case...
'netmask' should really be avoided these days, in preference to 'prefix' since the latter works for IPv4 and IPv6, while the former only works for IPv4. 'netmask' can be auto-calculated from 'prefix' by apps if they really care about it.
Fine by me, just that I think they should be hold by 2 separate attributes or element if possible at this point.
Yes, good point; and I don't know what I was thinking when I made the address attribute optional. I'll change the schema to this: <element name="ip"> <attribute name="address"><ref name="ip-addr"/></attribute> <attribute name="prefix"><ref name="prefix-pattern"/></attribute> </element> so that you'll write <ip address="172.32.12.10" prefix="24"/> I haven't declared the schema or the API stable yet, but I want to do that once there is a libvirt release out there that relies on netcf. So if there are any other issues with any of these aspects, raise them now or forever hold your peace. David
On Wed, Jun 17, 2009 at 01:27:14PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 22:10 +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 09:03:32PM +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 09:42:11PM +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 12:22:13PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote:
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured.
BTW I was looking at the Relax-NG grammar and found the following confusing when providing an IP address:
<element name="ip"> <optional> <attribute name="address"><ref name="ip-mask"/></attribute> </optional> </element>
I'm not really sure what ip-mask really means, are you trying to put in a single attribute both the IP address and the netmask ? If that's the case I would really suggest to split the two as separated IP and netmask in the XML structure, either separate attributes or another element for the netmask. Best to us the explicit structure of XML than a construct hidden inside the text field, unless I misunderstood the use case...
'netmask' should really be avoided these days, in preference to 'prefix' since the latter works for IPv4 and IPv6, while the former only works for IPv4. 'netmask' can be auto-calculated from 'prefix' by apps if they really care about it.
Fine by me, just that I think they should be hold by 2 separate attributes or element if possible at this point.
Yes, good point; and I don't know what I was thinking when I made the address attribute optional.
I'll change the schema to this:
<element name="ip"> <attribute name="address"><ref name="ip-addr"/></attribute> <attribute name="prefix"><ref name="prefix-pattern"/></attribute> </element>
so that you'll write
<ip address="172.32.12.10" prefix="24"/>
ACK, that gets my vote.
I haven't declared the schema or the API stable yet, but I want to do that once there is a libvirt release out there that relies on netcf. So if there are any other issues with any of these aspects, raise them now or forever hold your peace.
How do you deal with IPv6 currently ? I was thinking of sugesting an attribute <ip type="ipv6" address="2001:23::2" prefix="24"/> but I think its possibly better to have a different element name <ip6 address="2001:23::2" prefix="24"/> since the former would not work if we ever needed to worry about non-IP based addresses. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Wed, 2009-06-17 at 21:32 +0100, Daniel P. Berrange wrote:
How do you deal with IPv6 currently ?
With lots of Aspirin (actually, not at all)
I was thinking of sugesting an attribute
<ip type="ipv6" address="2001:23::2" prefix="24"/>
but I think its possibly better to have a different element name
<ip6 address="2001:23::2" prefix="24"/>
since the former would not work if we ever needed to worry about non-IP based addresses.
Either works for me, with a slight preference for the first version, on purely esthetic grounds. And even if we go with that, there's nothing keeping us from adding an <ipx> element as an alternative to the <ip> element in the future. David
On Wed, Jun 17, 2009 at 10:59:20PM +0000, David Lutterkort wrote:
On Wed, 2009-06-17 at 21:32 +0100, Daniel P. Berrange wrote:
How do you deal with IPv6 currently ?
With lots of Aspirin (actually, not at all)
I was thinking of sugesting an attribute
<ip type="ipv6" address="2001:23::2" prefix="24"/>
but I think its possibly better to have a different element name
<ip6 address="2001:23::2" prefix="24"/>
since the former would not work if we ever needed to worry about non-IP based addresses.
Either works for me, with a slight preference for the first version, on purely esthetic grounds. And even if we go with that, there's nothing keeping us from adding an <ipx> element as an alternative to the <ip> element in the future.
Or a 3rd option is to group addresses by family <addresses family='ipv4'> <ip address='122.0.0.3' prefix='24'/> <ip address='24.24.224.4' prefix='24'/> </addresses> <addresses family='ipv6'> <ip address='2001:23::2' prefix='48'/> <ip address='fe:33:55::33' prefix='64'/> </addresses> <adddresses family='ipx'> <ipx address='2423.4521.66.3.252.'/> </address> Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, Jun 18, 2009 at 10:46:45AM +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 10:59:20PM +0000, David Lutterkort wrote:
On Wed, 2009-06-17 at 21:32 +0100, Daniel P. Berrange wrote:
How do you deal with IPv6 currently ?
With lots of Aspirin (actually, not at all)
Very very very slowly ... I remember in 96 IETF meetings the propaganda that we were doomed if we didn't switch *right now* >:-> I also saw major brands of routers failing in faily nefastous ways when anxious people activated IPv6 a bit before everybody else. But jokes apart we need to have this working now ...
I was thinking of sugesting an attribute
<ip type="ipv6" address="2001:23::2" prefix="24"/>
but I think its possibly better to have a different element name
<ip6 address="2001:23::2" prefix="24"/>
since the former would not work if we ever needed to worry about non-IP based addresses.
Either works for me, with a slight preference for the first version, on purely esthetic grounds. And even if we go with that, there's nothing keeping us from adding an <ipx> element as an alternative to the <ip> element in the future.
Or a 3rd option is to group addresses by family
<addresses family='ipv4'> <ip address='122.0.0.3' prefix='24'/> <ip address='24.24.224.4' prefix='24'/> </addresses> <addresses family='ipv6'> <ip address='2001:23::2' prefix='48'/> <ip address='fe:33:55::33' prefix='64'/> </addresses> <adddresses family='ipx'> <ipx address='2423.4521.66.3.252.'/> </address>
Hum, right now the syntax is far more restrictive for addressing, there is one address, period, with an optional route we need to extend that IMHO. [...] The problem with the propsal is that it opens the door to a variety of errors like using the same familly twice, which I would like to avoid at the RNG level but it's not trivial. We should allow standalone IPv4 and IPv6, or both. Each could either use DHCP or allow one or more IP address and routes. I think if we have routes, at most one need to be a gateway and the other ones having destination + prefix. So I suggest the following rewrite of interface-addressing <!-- Assignment of IP address to an interface --> <define name="interface-addressing"> <choice> <ref name="interface-addr-ipv4"/> <ref name="interface-addr-ipv6"/> <group> <ref name="interface-addr-ipv4"/> <ref name="interface-addr-ipv6"/> </group> </choice> </define> This allows one or 2 blocks of addresses ipv4, ipv6 or both <define name="interface-addr-ipv4"> <element name="addresses"> <attribute name="family"> <value>ipv4</value> </attribute> <choice> <ref name="interface-addr-static"/> <ref name="interface-addr-dhcp"/> </choice> </element> </define> An IPv4 addresses block, allows for either static or dhcp <define name="interface-addr-ipv6"> <element name="addresses"> <attribute name="family"> <value>ipv6</value> </attribute> <choice> <ref name="interface-addr-static"/> <ref name="interface-addr-dhcp"/> </choice> </element> </define> same for IPv6 <define name="interface-addr-static"> <oneOrMore> <element name="ip"> <attribute name="address"><ref name="ip-addr"/></attribute> <attribute name="prefix"><ref name="prefix-pattern"/></attribute> </element> </oneOrMore> <optional> <ref name="interface-addr-routes"/> </optional> </define> A static addressing scheme is made of one or more <ip> elements with address and prefix followed by optional routing info <define name="interface-addr-dhcp"> <element name="dhcp"> <optional> <attribute name="peerdns"> <ref name="yes-or-no"/> </attribute> </optional> </element> </define> For DHCP the only option is the peerdns yes/no attribute <define name="interface-addr-routes"> <element name="route"> <attribute name="destination"> <value>default</value> </attribute> <attribute name="gateway"><ref name="ip-addr"/></attribute> </element> <zeroOrMore> <element name="route"> <attribute name="destination"><ref name="ip-addr"/></attribute> <attribute name="prefix"><ref name="prefix-pattern"/></attribute> <optional> <attribute name="gateway"><ref name="ip-addr"/></attribute> </optional> </element> </zeroOrMore> </define> And for routes we have at least one default route and then an optional set of routes with prefixes and optional gateways for that device. To note all the ip/dhcp/route constructs are similar for IPv4 and IPv6 as we don't check content precisely here. I assume it's sufficient. I think this revamps the capabilities quite a bit but I guess it should make sure we have IPv6 support on equal footing, and also incorporates I think most of Jim Fehlig remaks noted in the RNG. Examples of working definitions: <interface type="ethernet" startmode="onboot"> <name>eth1</name> <mtu size="1500"/> <mac address="00:1A:A0:8F:39:A6"/> <addresses family='ipv4'> <dhcp peerdns="no"/> </addresses> </interface> <interface type="ethernet" startmode="none"> <name>eth2</name> <addresses family='ipv4'> <dhcp/> </addresses> <addresses family='ipv6'> <dhcp/> </addresses> </interface> <interface type="ethernet" startmode="hotplug"> <name>eth3</name> <mac address="00:1A:A0:8F:50:B7"/> <addresses family='ipv4'> <ip address="192.168.0.15" prefix="24"/> <ip address="192.168.1.10" prefix="24"/> <route destination="default" gateway="192.168.0.1"/> <route destination="192.168.1.0" prefix="24" gateway="192.168.1.1"/> </addresses> </interface> This makes parsing a bit heavier, and I didn't checked if this really affected bridging and bonding interfaces in a wrong way, but I think that at least at an ethernet level definition this looks more complete. That said I have no idea how much of a problem it would be on the netcf impletmentation side. Daniel P.S.: full rng attached, double check the prefix-pattern definition I have no idea if it's sufficient for Ipv6 -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Thu, Jun 18, 2009 at 04:06:40PM +0200, Daniel Veillard wrote:
On Thu, Jun 18, 2009 at 10:46:45AM +0100, Daniel P. Berrange wrote:
I was thinking of sugesting an attribute
<ip type="ipv6" address="2001:23::2" prefix="24"/>
but I think its possibly better to have a different element name
<ip6 address="2001:23::2" prefix="24"/>
since the former would not work if we ever needed to worry about non-IP based addresses.
Either works for me, with a slight preference for the first version, on purely esthetic grounds. And even if we go with that, there's nothing keeping us from adding an <ipx> element as an alternative to the <ip> element in the future.
Or a 3rd option is to group addresses by family
<addresses family='ipv4'> <ip address='122.0.0.3' prefix='24'/> <ip address='24.24.224.4' prefix='24'/> </addresses> <addresses family='ipv6'> <ip address='2001:23::2' prefix='48'/> <ip address='fe:33:55::33' prefix='64'/> </addresses> <adddresses family='ipx'> <ipx address='2423.4521.66.3.252.'/> </address>
Hum, right now the syntax is far more restrictive for addressing, there is one address, period, with an optional route we need to extend that IMHO.
[...]
The problem with the propsal is that it opens the door to a variety of errors like using the same familly twice, which I would like to avoid at the RNG level but it's not trivial.
We should allow standalone IPv4 and IPv6, or both. Each could either use DHCP or allow one or more IP address and routes.
You need to have allow for IP adddresses & routes to be present even when doing DHCP, because you need to discover what was auto-configured.
I think if we have routes, at most one need to be a gateway and the other ones having destination + prefix.
So I suggest the following rewrite of interface-addressing
<!-- Assignment of IP address to an interface --> <define name="interface-addressing"> <choice> <ref name="interface-addr-ipv4"/> <ref name="interface-addr-ipv6"/> <group> <ref name="interface-addr-ipv4"/> <ref name="interface-addr-ipv6"/> </group> </choice> </define>
This allows one or 2 blocks of addresses ipv4, ipv6 or both
This is overly strict, because it does not allow for an interface without any addresses - something you want todo if configuring a bridge device just for guest traffic and do not want any IP on it for the host. So just need to make both optional <define name="interface-addressing"> <group> <optional> <ref name="interface-addr-ipv4"/> <optional> <optional> <ref name="interface-addr-ipv6"/> <optional> </group> </define>
<define name="interface-addr-ipv4"> <element name="addresses"> <attribute name="family"> <value>ipv4</value> </attribute> <choice> <ref name="interface-addr-static"/> <ref name="interface-addr-dhcp"/> </choice> </element> </define>
An IPv4 addresses block, allows for either static or dhcp
<define name="interface-addr-ipv6"> <element name="addresses"> <attribute name="family"> <value>ipv6</value> </attribute> <choice> <ref name="interface-addr-static"/> <ref name="interface-addr-dhcp"/> </choice> </element> </define>
same for IPv6
Not quite - IPv6 needs to allow for more options - static - fully manual setup - autoconf - auto assign addresses/routes. Assume DNS etc via dhcpv4 or manual - autoconf + statless dhcp - auto assign addresses/routes. DNS etc via dhcpv6 - statefull dhcp - everything via dhcpv6 Check out this preso for an overview if you dare. http://lacnic.net/documentos/lacnicxi/presentaciones/autoconf_and_dhcpv6.pdf In all cases we need to include <ip> tags to show the manual, or automatically configured addresses/routes.
<define name="interface-addr-static"> <oneOrMore> <element name="ip"> <attribute name="address"><ref name="ip-addr"/></attribute> <attribute name="prefix"><ref name="prefix-pattern"/></attribute> </element> </oneOrMore> <optional> <ref name="interface-addr-routes"/> </optional> </define>
A static addressing scheme is made of one or more <ip> elements with address and prefix followed by optional routing info
<define name="interface-addr-dhcp"> <element name="dhcp"> <optional> <attribute name="peerdns"> <ref name="yes-or-no"/> </attribute> </optional> </element> </define>
For DHCP the only option is the peerdns yes/no attribute
<define name="interface-addr-routes"> <element name="route"> <attribute name="destination"> <value>default</value> </attribute> <attribute name="gateway"><ref name="ip-addr"/></attribute> </element> <zeroOrMore> <element name="route"> <attribute name="destination"><ref name="ip-addr"/></attribute> <attribute name="prefix"><ref name="prefix-pattern"/></attribute> <optional> <attribute name="gateway"><ref name="ip-addr"/></attribute> </optional> </element> </zeroOrMore> </define>
And for routes we have at least one default route and then an optional set of routes with prefixes and optional gateways for that device. To note all the ip/dhcp/route constructs are similar for IPv4 and IPv6 as we don't check content precisely here. I assume it's sufficient.
The 'ip-addr' match rule will need separate rules for IPv4 vs IP6 addresses, since the former use '.' as a seprator, while the latter use ':'. The 'prefix-pattern' can be same, since its just a number
<interface type="ethernet" startmode="onboot"> <name>eth1</name> <mtu size="1500"/> <mac address="00:1A:A0:8F:39:A6"/> <addresses family='ipv4'> <dhcp peerdns="no"/>
..... possible <ip> tag(s) here if interface is active
</addresses> </interface>
<interface type="ethernet" startmode="none"> <name>eth2</name> <addresses family='ipv4'> <dhcp/> </addresses> <addresses family='ipv6'> <dhcp/>
This also needs to indicate whether 'autoconf' is on vs off. Probably just want an <autoconf/> element for that with any combo of '<dhcp/>' and '<autoconf/>' allowed, including neither.
</addresses> </interface>
<interface type="ethernet" startmode="hotplug"> <name>eth3</name> <mac address="00:1A:A0:8F:50:B7"/> <addresses family='ipv4'> <ip address="192.168.0.15" prefix="24"/> <ip address="192.168.1.10" prefix="24"/> <route destination="default" gateway="192.168.0.1"/> <route destination="192.168.1.0" prefix="24" gateway="192.168.1.1"/> </addresses> </interface>
This makes parsing a bit heavier, and I didn't checked if this really affected bridging and bonding interfaces in a wrong way, but I think that at least at an ethernet level definition this looks more complete.
That said I have no idea how much of a problem it would be on the netcf impletmentation side.
Daniel
P.S.: full rng attached, double check the prefix-pattern definition I have no idea if it's sufficient for Ipv6
The prefix is fine. the ip address rule needs to allow ':' for IPv6.
<!-- A Relax NG schema for network interfaces --> <grammar xmlns="http://relaxng.org/ns/structure/1.0" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes"> <start> <choice> <ref name="ethernet-interface"/> <ref name="bridge-interface"/> <ref name="bond-interface"/> </choice> </start>
<!-- FIXME: How do we handle VLAN's ? Should they be their own interface or should we treat them as an option on the base interface ? For example, for vlan eth0.42, it would make sense to make that part of the definition of the eth0 interface. -->
VLANs are tricky, because you can define VLANs on a physical inteface or a bond interface, and you then may want to also add a bridge on top of a VLAN, eg take 2 physical NICs, eth0 and eth1, here are some possible combes - One NIC for storage, another for host mgmt, and put the guests all on VLANs eth0 -> br0 IP addr used for storage eth1 -> br1 IP addr used for host mgmt eth1.42 -> br1.42 IP addr, used to talk to guests eth1.43 -> br1.43 No IP, guest traffic only eth1.44 -> br1.44 No IP, guest traffic only - Bonded NICs, used for everything eth0 + eth1 -> bond0 -> br0 IP addr used for all - Bonded NICs, and VLANs for guests eth0 + eth1 -> bond0 IP addr used for host admin+storage bond0.42 -> br0.42 IP addr, used to talk to guests bond0.43 -> br0.43 No IP, guest traffic only - Bonded NICs, and VLANs for host and for guests eth0 + eth1 -> bond0 No IP, not used directly. bond0.42 IP addr, Host mgmt traffic bond0.43 -> br0.43 No IP, guest traffic only I think the currently approach of modelling bond, bridges and NICs makes this a little hard, particularly if the netcf API only exposes 'connections' and not interfaces, because some of these setups are not really connections, only building blocks for 'n' other connections Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, Jun 18, 2009 at 06:06:27PM +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 04:06:40PM +0200, Daniel Veillard wrote:
<define name="interface-addr-ipv6"> <element name="addresses"> <attribute name="family"> <value>ipv6</value> </attribute> <choice> <ref name="interface-addr-static"/> <ref name="interface-addr-dhcp"/> </choice> </element> </define>
same for IPv6
Not quite - IPv6 needs to allow for more options
- static - fully manual setup - autoconf - auto assign addresses/routes. Assume DNS etc via dhcpv4 or manual - autoconf + statless dhcp - auto assign addresses/routes. DNS etc via dhcpv6 - statefull dhcp - everything via dhcpv6
Of course there's also the need for a 'none' case. My proposal for <addresses family=''> element intended that to be implied.
Check out this preso for an overview if you dare.
http://lacnic.net/documentos/lacnicxi/presentaciones/autoconf_and_dhcpv6.pdf
In all cases we need to include <ip> tags to show the manual, or automatically configured addresses/routes.
Some examples might help understand all these options 1. no IPv6 sysconfig file: IPV6=no XML ...no <addresses> element for IPv6 2. IPv6 link local only, no autoconf, no static address, no dhcp IPV6=yes IPV6_AUTOCONF=no DHCPV6=no XML to define it <addresses family='ipv6'/> XML when running <addresses family='ipv6'> <ip address="fe80::215:58ff:fe6e:5" prefix="64"/> (the link local addr) </addresses> 3. IPv6 link local, no autoconf, one static address, no dhcp IPV6=yes IPV6_AUTOCONF=no DHCPV6=no IPV6ADDR="3ffe:ffff:0:5::1" XML to define it <addresses family='ipv6'> <ip address="3ffe:ffff:0:5::1" prefix="128"/> (the static addr) </addresses> XML when running <addresses family='ipv6'> <ip address="fe80::215:58ff:fe6e:5" prefix="64"/> (the link local addr) <ip address="3ffe:ffff:0:5::1" prefix="128"/> (the static addr) </addresses> 4. IPv6 link local, autoconf, no static address, no dhcp IPV6=yes IPV6_AUTOCONF=yes DHCPV6=no XML to define it <addresses family='ipv6'> <autoconf/> </addresses> XML when running <addresses family='ipv6'> <autoconf/> <ip address="fe80::215:58ff:fe6e:5" prefix="64"/> (the link local addr) <ip address="3ffe:1234:0:5::6" prefix="128"/> (the automatic addr) </addresses> 5. IPv6 link local, autoconf, no static address, dhcp for services IPV6=yes IPV6_AUTOCONF=yes DHCPV6=yes XML to define it <addresses family='ipv6'> <autoconf/> <dhcp/> </addresses> XML when running <addresses family='ipv6'> <autoconf/> <dhcp/> <ip address="fe80::215:58ff:fe6e:5" prefix="64"/> (the link local addr) <ip address="3ffe:1234:0:5::6" prefix="128"/> (the automatic addr) </addresses> 6. IPv6 link local, no autoconf, no static address, dhcp for everything IPV6=yes IPV6_AUTOCONF=no DHCPV6=yes XML to define it <addresses family='ipv6'> <dhcp/> </addresses> XML when running <addresses family='ipv6'> <autoconf/> <dhcp/> <ip address="fe80::215:58ff:fe6e:5" prefix="64"/> (the link local addr) <ip address="3ffe:7891:0:5::6" prefix="128"/> (the dhcp addr) </addresses> It may be aso possible to list extra static addresses, even while autoconf and/or dhcp are enabled. Can't remember off hand. Basically every single combo you can think of is probably needed. For brevity, i left out routes here. You can more or less asume zero or more routes are needed in all these scenarios. Regards, Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, 2009-06-18 at 18:06 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 04:06:40PM +0200, Daniel Veillard wrote:
We should allow standalone IPv4 and IPv6, or both. Each could either use DHCP or allow one or more IP address and routes.
You need to have allow for IP adddresses & routes to be present even when doing DHCP, because you need to discover what was auto-configured.
That only makes sense when reading an existing config, with the meaning 'the interface uses DHCP when it is brought up, and has the following address currently assigned to it'; it makes no sense when using the XML to configure a device. I would prefer for that case a separate API call to ask for currently assigned addresses.
This is overly strict, because it does not allow for an interface without any addresses - something you want todo if configuring a bridge device just for guest traffic and do not want any IP on it for the host. So just need to make both optional
You can achieve the same by making interface-addressing optional where it is used.
Check out this preso for an overview if you dare.
http://lacnic.net/documentos/lacnicxi/presentaciones/autoconf_and_dhcpv6.pdf
Need to read that first.
The 'ip-addr' match rule will need separate rules for IPv4 vs IP6 addresses, since the former use '.' as a seprator, while the latter use ':'. The 'prefix-pattern' can be same, since its just a number
The valid range for prefix-pattern differs, and we should therefore between the two.
VLANs are tricky, because you can define VLANs on a physical inteface or a bond interface, and you then may want to also add a bridge on top of a VLAN, eg take 2 physical NICs, eth0 and eth1, here are some possible combes
- One NIC for storage, another for host mgmt, and put the guests all on VLANs
eth0 -> br0 IP addr used for storage eth1 -> br1 IP addr used for host mgmt eth1.42 -> br1.42 IP addr, used to talk to guests eth1.43 -> br1.43 No IP, guest traffic only eth1.44 -> br1.44 No IP, guest traffic only
I don't think that's the right notation, don't you mean 'eth1.42 -> br2' etc. ?
I think the currently approach of modelling bond, bridges and NICs makes this a little hard, particularly if the netcf API only exposes 'connections' and not interfaces, because some of these setups are not really connections, only building blocks for 'n' other connections
For that, you'd nest them where they are used, e.g. one connection to establish the base ethernet interface (that might not exist at all): <interface type="ethernet" startmode="none"> <name>eth0</name> <mtu size="1492"/> <mac address="aa:bb:cc:dd:ee:ff"/> <dhcp peerdns="no"/> </interface> and one for the bridge with a vlan enslaved: <interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="vlan" device="eth0" tag="42"/> </bridge> </interface> Similarly, a bond enslaved to a bridge, together with a vlan on that bond also enslaved to the bridge would look like <interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="bond"> <name>bond0</name> <bond mode="active-backup"> <interface type="ethernet"> <name>eth1</name> </interface> <interface type="ethernet"> <name>eth0</name> </interface> </bond> </interface> <interface type="vlan" device="bond0" tag="42"/> </bridge> </interface> David
On Thu, Jun 18, 2009 at 05:53:59PM +0000, David Lutterkort wrote:
On Thu, 2009-06-18 at 18:06 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 04:06:40PM +0200, Daniel Veillard wrote:
We should allow standalone IPv4 and IPv6, or both. Each could either use DHCP or allow one or more IP address and routes.
You need to have allow for IP adddresses & routes to be present even when doing DHCP, because you need to discover what was auto-configured.
That only makes sense when reading an existing config, with the meaning 'the interface uses DHCP when it is brought up, and has the following address currently assigned to it'; it makes no sense when using the XML to configure a device.
I would prefer for that case a separate API call to ask for currently assigned addresses.
This is overly strict, because it does not allow for an interface without any addresses - something you want todo if configuring a bridge device just for guest traffic and do not want any IP on it for the host. So just need to make both optional
You can achieve the same by making interface-addressing optional where it is used.
Check out this preso for an overview if you dare.
http://lacnic.net/documentos/lacnicxi/presentaciones/autoconf_and_dhcpv6.pdf
Need to read that first.
The 'ip-addr' match rule will need separate rules for IPv4 vs IP6 addresses, since the former use '.' as a seprator, while the latter use ':'. The 'prefix-pattern' can be same, since its just a number
The valid range for prefix-pattern differs, and we should therefore between the two.
VLANs are tricky, because you can define VLANs on a physical inteface or a bond interface, and you then may want to also add a bridge on top of a VLAN, eg take 2 physical NICs, eth0 and eth1, here are some possible combes
- One NIC for storage, another for host mgmt, and put the guests all on VLANs
eth0 -> br0 IP addr used for storage eth1 -> br1 IP addr used for host mgmt eth1.42 -> br1.42 IP addr, used to talk to guests eth1.43 -> br1.43 No IP, guest traffic only eth1.44 -> br1.44 No IP, guest traffic only
I don't think that's the right notation, don't you mean 'eth1.42 -> br2' etc. ?
I think the currently approach of modelling bond, bridges and NICs makes this a little hard, particularly if the netcf API only exposes 'connections' and not interfaces, because some of these setups are not really connections, only building blocks for 'n' other connections
For that, you'd nest them where they are used, e.g. one connection to establish the base ethernet interface (that might not exist at all):
<interface type="ethernet" startmode="none"> <name>eth0</name> <mtu size="1492"/> <mac address="aa:bb:cc:dd:ee:ff"/> <dhcp peerdns="no"/> </interface>
and one for the bridge with a vlan enslaved:
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="vlan" device="eth0" tag="42"/> </bridge> </interface>
Similarly, a bond enslaved to a bridge, together with a vlan on that bond also enslaved to the bridge would look like
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="bond"> <name>bond0</name> <bond mode="active-backup"> <interface type="ethernet"> <name>eth1</name> </interface> <interface type="ethernet"> <name>eth0</name> </interface> </bond> </interface> <interface type="vlan" device="bond0" tag="42"/> </bridge> </interface>
I think this is a really unpleasant format to deal with. IMHO there should not be nesting for <bridge>/<bond> tags. They should just refer to their slave device by name. So that last example would be better shown as a set of independant intefaces <interface type='bond'> <name>bond0</name> <bond mode="active-backup"> <interface name='eth0'/> <interface name='eth1'/> </bond> </interface> <interface type='vlan'> <name>bond0.42</name> <vlan tag='42'> <interface name='bond0'> </bridge> </interface> <interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface name="bond0.42"/> </bridge> <interface> If you added more vlans, then they just appear as more interfaces at the top level <interface type='vlan'> <name>bond0.47</name> <vlan tag='47'> <interface name='bond0'> </bridge> </interface> <interface type='vlan'> <name>bond0.48</name> <vlan tag='48'> <interface name='bond0'> </bridge> </interface> Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, Jun 18, 2009 at 07:05:29PM +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 05:53:59PM +0000, David Lutterkort wrote:
For that, you'd nest them where they are used, e.g. one connection to establish the base ethernet interface (that might not exist at all):
<interface type="ethernet" startmode="none"> <name>eth0</name> <mtu size="1492"/> <mac address="aa:bb:cc:dd:ee:ff"/> <dhcp peerdns="no"/> </interface>
and one for the bridge with a vlan enslaved:
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="vlan" device="eth0" tag="42"/> </bridge> </interface>
Similarly, a bond enslaved to a bridge, together with a vlan on that bond also enslaved to the bridge would look like
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="bond"> <name>bond0</name> <bond mode="active-backup"> <interface type="ethernet"> <name>eth1</name> </interface> <interface type="ethernet"> <name>eth0</name> </interface> </bond> </interface> <interface type="vlan" device="bond0" tag="42"/> </bridge> </interface>
I think this is a really unpleasant format to deal with. IMHO there should not be nesting for <bridge>/<bond> tags. They should just refer to their slave device by name. So that last example would be better shown as a set of independant intefaces
Rationalizing the reason why I don't like this format. The relationship of NICs essentially forms a DAG. This format is attempting to define a tree from the POV of a single leaf node. So to deal with multiple leaf nodes you either end up having signficantly overlapping configs between leaves, or have one leaf defining the main branch, and other leaves only defining sub-branches. I don't think either is really satisfactory, and can be avoiding by defining a flat list of interfaces, and encoding the parent/ child relationships in each. An application using this, still retains the flexibility to display the information in the structure that is most suitable for its needs, be it paths from the POV of a leaf, paths from the POV of a root, the entire tree in one, or flat lists, or some other hybrid.
<interface type='bond'> <name>bond0</name> <bond mode="active-backup"> <interface name='eth0'/> <interface name='eth1'/> </bond> </interface>
So this shows children, while the XML for the physical interface could show the inverse. <interface type='physical'> <name>eth0</name> <master> <interface name='bond0'/> </master> </interface> The API contract might wish to specify the order for defining new interfaces, eg whether to require the bond0 to be defined first and then physical interfaces added, whether physical members must be defined first & then the bond, or whether creation of the bon0 automatically implies that interfaces for eth0/eth1 appear in the list. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, 2009-06-18 at 20:48 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 07:05:29PM +0100, Daniel P. Berrange wrote:
I think this is a really unpleasant format to deal with. IMHO there should not be nesting for <bridge>/<bond> tags. They should just refer to their slave device by name. So that last example would be better shown as a set of independant intefaces
Rationalizing the reason why I don't like this format. The relationship of NICs essentially forms a DAG. This format is attempting to define a tree from the POV of a single leaf node.
They do form a tree, with the exception of VLAN's: every other instance of an interface can be contained/used by at most one other interface. We need to treat VLAN's a little special, and allow them to reference external (to the XML) interfaces.
An application using this, still retains the flexibility to display the information in the structure that is most suitable for its needs, be it paths from the POV of a leaf, paths from the POV of a root, the entire tree in one, or flat lists, or some other hybrid.
I don't think that what an application can display is hindered by any of the formats we've been discussing. To me, the overriding concerns are (a) exposing as much as possible for static checks in the RelaxNG grammar and (b) avoid writing the representation in a way that causes undue headaches in some of the backends we'll eventually need, by assuming e.g. we can write out the config for a partial interface.
<interface type='bond'> <name>bond0</name> <bond mode="active-backup"> <interface name='eth0'/> <interface name='eth1'/> </bond> </interface>
So this shows children, while the XML for the physical interface could show the inverse.
The importnat thing is that it has parent/child relations going both ways in one place, and therefore is much less likely to cause headache, no matter whether the config backend writes its config files in a more child->parent oriented manner (like initscripts) or in a parent->child oriented manner (like Debian[1])
<interface type='physical'> <name>eth0</name> <master> <interface name='bond0'/> </master> </interface>
No; we need to come up with _one_ way to express 'bond0 consists of eth0 and eth1', not multiple ways. There's no value in that, only headache; enterprising souls are free to create alternate views of the XML with their favorite XSL stylesheet - something tha the nested representation makes easier.
The API contract might wish to specify the order for defining new interfaces, eg whether to require the bond0 to be defined first and then physical interfaces added, whether physical members must be defined first & then the bond, or whether creation of the bon0 automatically implies that interfaces for eth0/eth1 appear in the list.
If you do that, you require that netcf stores some data in some lookaside location - with your last example above, on Debian, nothing can be written to /etc/network/interfaces, until the actual bond device is defined. Also, what would it mean if bond0 already exists (say, bonding eth1 and eth2) and an interface is defined with the above XML snippet ? Do eth1 and eth2 stay in the bond ? If so, how do you get rid of eth2 in the bond ? David [1] http://wiki.debian.org/Bonding
On Thu, Jun 18, 2009 at 10:50:10PM +0000, David Lutterkort wrote:
On Thu, 2009-06-18 at 20:48 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 07:05:29PM +0100, Daniel P. Berrange wrote:
I think this is a really unpleasant format to deal with. IMHO there should not be nesting for <bridge>/<bond> tags. They should just refer to their slave device by name. So that last example would be better shown as a set of independant intefaces
Rationalizing the reason why I don't like this format. The relationship of NICs essentially forms a DAG. This format is attempting to define a tree from the POV of a single leaf node.
They do form a tree, with the exception of VLAN's: every other instance of an interface can be contained/used by at most one other interface. We need to treat VLAN's a little special, and allow them to reference external (to the XML) interfaces.
Trying to digest that long discussion maybe there is a solution: - Dan thin a pure tree representation is not sufficient to express all relationships between interfaces - Dave would like to preserve the ability run the checks on a single XML instance I think both can be accomodated but that requires a slight change of API, i.e. the XML will be able to define a set of interfaces. Basically we could do <interfaces> <!-- define the set of physical interfaces --> <interface ... name="eth0" ..> .... </interface> <interface name="eth1" ...> .... </interface> ... <!-- then define bonding, bridging and vlans --> <bond mode="active-backup"> <source name="eth0"/> <source name="eth1"/> </bond> <bridge name="br0"> <mtu size="1500"/> <dhcp/> <source name="eth3"/> </bridge> <vlan> .... </vlan> </interfaces> I think this solves the expressiveness issues raised by Dan, I think we can still do the checking at validation time (note that I moved name as attributes which makes it nearly trivial using ID/IDREF in DTD/RNG or even XSD) I think this makes way cleaner the definition of interface for example in a bridge situation, the underlying ethernet really ought to be a first class citizen not have it's definition pushed down inside the bridge just because it's currently used to that. The <interfaces> description would still internally be chunked out so that you could invoke the API to get a part of the whole set, you may just get an <interface> <bridge>, <bond> or <vlan>, which could still be used to modify parameters. I also feel this may avoid races in definitions where we want a bunch of separate but related interfaces needed for a service, and doing it in one API call may allow to do thing in a more atomic fashion. The main problem is that it departs seriously from the existing netcf format and API design, and the XSLT processing may be a bit harder (but not that much I expect), I can write a schemas for this with updates based on feedback for the previous version . Opinions ? Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Fri, Jun 19, 2009 at 06:13:37PM +0200, Daniel Veillard wrote:
On Thu, Jun 18, 2009 at 10:50:10PM +0000, David Lutterkort wrote:
On Thu, 2009-06-18 at 20:48 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 07:05:29PM +0100, Daniel P. Berrange wrote:
I think this is a really unpleasant format to deal with. IMHO there should not be nesting for <bridge>/<bond> tags. They should just refer to their slave device by name. So that last example would be better shown as a set of independant intefaces
Rationalizing the reason why I don't like this format. The relationship of NICs essentially forms a DAG. This format is attempting to define a tree from the POV of a single leaf node.
They do form a tree, with the exception of VLAN's: every other instance of an interface can be contained/used by at most one other interface. We need to treat VLAN's a little special, and allow them to reference external (to the XML) interfaces.
Trying to digest that long discussion maybe there is a solution:
- Dan thin a pure tree representation is not sufficient to express all relationships between interfaces - Dave would like to preserve the ability run the checks on a single XML instance
I think both can be accomodated but that requires a slight change of API, i.e. the XML will be able to define a set of interfaces. Basically we could do
Urgh, no I think that's even worse. I'd prefer either of the 2 options we've currently discussed over that. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Fri, 2009-06-19 at 17:17 +0100, Daniel P. Berrange wrote:
On Fri, Jun 19, 2009 at 06:13:37PM +0200, Daniel Veillard wrote:
On Thu, Jun 18, 2009 at 10:50:10PM +0000, David Lutterkort wrote:
On Thu, 2009-06-18 at 20:48 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 07:05:29PM +0100, Daniel P. Berrange wrote:
I think this is a really unpleasant format to deal with. IMHO there should not be nesting for <bridge>/<bond> tags. They should just refer to their slave device by name. So that last example would be better shown as a set of independant intefaces
Rationalizing the reason why I don't like this format. The relationship of NICs essentially forms a DAG. This format is attempting to define a tree from the POV of a single leaf node.
They do form a tree, with the exception of VLAN's: every other instance of an interface can be contained/used by at most one other interface. We need to treat VLAN's a little special, and allow them to reference external (to the XML) interfaces.
Trying to digest that long discussion maybe there is a solution:
- Dan thin a pure tree representation is not sufficient to express all relationships between interfaces - Dave would like to preserve the ability run the checks on a single XML instance
I think both can be accomodated but that requires a slight change of API, i.e. the XML will be able to define a set of interfaces. Basically we could do
Urgh, no I think that's even worse. I'd prefer either of the 2 options we've currently discussed over that.
Agreed .. that format wouldn't help much with static checking. David
On Fri, Jun 19, 2009 at 05:45:33PM +0000, David Lutterkort wrote:
On Fri, 2009-06-19 at 17:17 +0100, Daniel P. Berrange wrote:
On Fri, Jun 19, 2009 at 06:13:37PM +0200, Daniel Veillard wrote:
On Thu, Jun 18, 2009 at 10:50:10PM +0000, David Lutterkort wrote:
On Thu, 2009-06-18 at 20:48 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 07:05:29PM +0100, Daniel P. Berrange wrote:
I think this is a really unpleasant format to deal with. IMHO there should not be nesting for <bridge>/<bond> tags. They should just refer to their slave device by name. So that last example would be better shown as a set of independant intefaces
Rationalizing the reason why I don't like this format. The relationship of NICs essentially forms a DAG. This format is attempting to define a tree from the POV of a single leaf node.
They do form a tree, with the exception of VLAN's: every other instance of an interface can be contained/used by at most one other interface. We need to treat VLAN's a little special, and allow them to reference external (to the XML) interfaces.
Trying to digest that long discussion maybe there is a solution:
- Dan thin a pure tree representation is not sufficient to express all relationships between interfaces - Dave would like to preserve the ability run the checks on a single XML instance
I think both can be accomodated but that requires a slight change of API, i.e. the XML will be able to define a set of interfaces. Basically we could do
Urgh, no I think that's even worse. I'd prefer either of the 2 options we've currently discussed over that.
Agreed .. that format wouldn't help much with static checking.
Okay, well I think the recursive definition is really the worse for validation and processing. And <interface> ... </interface> <interface> ... </interface> <interface> ... </interface> Means 3 distinct XML documents, and that you can do no static checking at all at least at the XML level. So I don't understand why you say it can't help with static checking. Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Fri, 2009-06-19 at 20:14 +0200, Daniel Veillard wrote:
On Fri, Jun 19, 2009 at 05:45:33PM +0000, David Lutterkort wrote:
Agreed .. that format wouldn't help much with static checking.
Okay, well I think the recursive definition is really the worse for validation and processing.
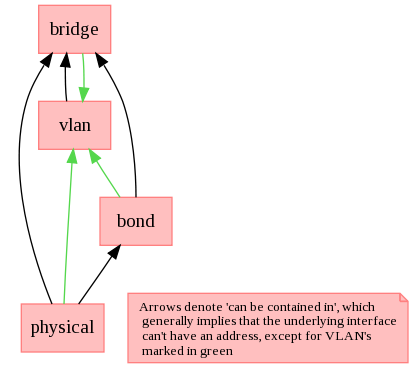
I think the nested format is the easiest to validate, and make sure we encode rules like "a bridge may not enslave another bridge" or "a bond can only enslave physical NIC's" Look at the picture[1] with the edges going into the vlan node removed - that's pretty much the structure of the RelaxNG. It's precise, and fairly simple. The main thing we are missing is a distinction between toplevel bond (may have an address) and enslaved bond (no address), similar to how the RelaxNG distinguishes between ethernet-interface and bare-ethernet-interface. David [1] https://fedorahosted.org/netcf/wiki/InterfaceNesting
On Thu, 2009-06-18 at 19:05 +0100, Daniel P. Berrange wrote:
Similarly, a bond enslaved to a bridge, together with a vlan on that bond also enslaved to the bridge would look like
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="bond"> <name>bond0</name> <bond mode="active-backup"> <interface type="ethernet"> <name>eth1</name> </interface> <interface type="ethernet"> <name>eth0</name> </interface> </bond> </interface> <interface type="vlan" device="bond0" tag="42"/> </bridge> </interface>
I think this is a really unpleasant format to deal with.
There's two reasons why I prefer that rather than splitting everything into multiple standalone <interface> tags: 1. When as many components of the overall interface/connection are in one place, more validation can be done in RelaxNG, i.e. statically 2. Because of this, it is easier for application writers to test and validate the XML they generate - most issues can be caught by validating against the RelaxNG, and fewer issues depend on doing things in the right order (for example, with the nested format, you cna never get into a situation where you enslave an undefined bond into a bridge) I assume what you find unpleasant is that when you generate the XML you need to embed one interface in another, though that seems to me mostly an issue in what order you do your sprintf's.
IMHO there should not be nesting for <bridge>/<bond> tags.
For <bond>, there's nothing to worry about, since all you can add to a bond are physical interfaces (since all the possible nesting gets confusing, I drew a little picture) vlans can't contain their underlying device, since there can be many vlan's used in multiple interfaces for a device. This is the one place in the format I suggested where we need an external reference check: we need to make sure that the interface underlying the vlan is already configured. Bridges, of course, are hopeless, since they are omnivorous. But again, with the nested format, all sanity checking can happen in RelaxNG, except for the referential integrity of vlan's.
They should just refer to their slave device by name. So that last example would be better shown as a set of independant intefaces
<interface type='bond'> <name>bond0</name> <bond mode="active-backup"> <interface name='eth0'/> <interface name='eth1'/> </bond> </interface>
This requires that you check that the interfaces named there are physical NIC's at runtime.
<interface type='vlan'> <name>bond0.42</name> <vlan tag='42'> <interface name='bond0'> </bridge> </interface>
I don't think there's a good case for setting the name of a VLAN explicitly. vconfig let's you choose from one of four naming modes, but I am not even sure it's worth exposing those in the XML.
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface name="bond0.42"/> </bridge> <interface>
At this point, you need to check that bond0.42 is defined, without any address setup.
If you added more vlans, then they just appear as more interfaces at the top level
I would really like to stick to a model where toplevel interfaces are the ones that aren't contained in other interface definitions anymore. David
{kind=link}
On 06/18/2009 01:53 PM, David Lutterkort wrote:
On Thu, 2009-06-18 at 18:06 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 04:06:40PM +0200, Daniel Veillard wrote:
We should allow standalone IPv4 and IPv6, or both. Each could either use DHCP or allow one or more IP address and routes.
You need to have allow for IP adddresses & routes to be present even when doing DHCP, because you need to discover what was auto-configured.
That only makes sense when reading an existing config, with the meaning 'the interface uses DHCP when it is brought up, and has the following address currently assigned to it'; it makes no sense when using the XML to configure a device.
I would prefer for that case a separate API call to ask for currently assigned addresses.
I agree that the API call to retrieve the current configuration should be separate from the API call to retrieve the current state of the interface. If you mix them, a "get config / write config" pair would no longer be a NOP (for example, you would end up with the IP addresses/routes obtained from DHCP being written into the config file, and that can't be good.)
On Thu, Jun 18, 2009 at 02:22:16PM -0400, Laine Stump wrote:
On 06/18/2009 01:53 PM, David Lutterkort wrote:
On Thu, 2009-06-18 at 18:06 +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 04:06:40PM +0200, Daniel Veillard wrote:
We should allow standalone IPv4 and IPv6, or both. Each could either use DHCP or allow one or more IP address and routes.
You need to have allow for IP adddresses & routes to be present even when doing DHCP, because you need to discover what was auto-configured.
That only makes sense when reading an existing config, with the meaning 'the interface uses DHCP when it is brought up, and has the following address currently assigned to it'; it makes no sense when using the XML to configure a device.
I would prefer for that case a separate API call to ask for currently assigned addresses.
I agree that the API call to retrieve the current configuration should be separate from the API call to retrieve the current state of the interface. If you mix them, a "get config / write config" pair would no longer be a NOP (for example, you would end up with the IP addresses/routes obtained from DHCP being written into the config file, and that can't be good.)
That is why the virInterfaceDumpXML() elements has a 'flags' argument. With no flags set it would return the config matching the interfaces' current state. If VIR_INTEFACE_INACTIVE is set, then it would always return the persistent offline config. So an app doing a read+modify+write sequence should always use VIR_INTERFACE_INACTIVE. This model matches that done for our other APIs. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, Jun 18, 2009 at 05:53:59PM +0000, David Lutterkort wrote:
On Thu, 2009-06-18 at 18:06 +0100, Daniel P. Berrange wrote:
VLANs are tricky, because you can define VLANs on a physical inteface or a bond interface, and you then may want to also add a bridge on top of a VLAN, eg take 2 physical NICs, eth0 and eth1, here are some possible combes
- One NIC for storage, another for host mgmt, and put the guests all on VLANs
eth0 -> br0 IP addr used for storage eth1 -> br1 IP addr used for host mgmt eth1.42 -> br1.42 IP addr, used to talk to guests eth1.43 -> br1.43 No IP, guest traffic only eth1.44 -> br1.44 No IP, guest traffic only
I don't think that's the right notation, don't you mean 'eth1.42 -> br2' etc. ?
Yes that was a mistake.
I think the currently approach of modelling bond, bridges and NICs makes this a little hard, particularly if the netcf API only exposes 'connections' and not interfaces, because some of these setups are not really connections, only building blocks for 'n' other connections
For that, you'd nest them where they are used, e.g. one connection to establish the base ethernet interface (that might not exist at all):
<interface type="ethernet" startmode="none"> <name>eth0</name> <mtu size="1492"/> <mac address="aa:bb:cc:dd:ee:ff"/> <dhcp peerdns="no"/> </interface>
and one for the bridge with a vlan enslaved:
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="vlan" device="eth0" tag="42"/> </bridge> </interface>
Similarly, a bond enslaved to a bridge, together with a vlan on that bond also enslaved to the bridge would look like
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="bond"> <name>bond0</name> <bond mode="active-backup"> <interface type="ethernet"> <name>eth1</name> </interface> <interface type="ethernet"> <name>eth0</name> </interface> </bond> </interface> <interface type="vlan" device="bond0" tag="42"/> </bridge> </interface>
Here is a proposal that is a compromise between the single hierarchy, and completely flat. The break point is only introduced where VLANs appear, which is acceptable because when defining VLAns, you don't need to define the underlying inteface at the same time - it can exist in its own right ahead of time. Only nic+bond or nics+bridge or nic+bond+bridge need to be atomically defined at once. There are 4 possible arrangements of physical NIC, bond and vlan, each of which can use a bridge. This gives 8 total configs 1. Physical NIC 2. Physical NIC + bridge 3. Physical NIC + bond 4. Physical NIC + bond + bridge 5. Physical NIC + vlan 6. Physical NIC + vlan + bridge 7. Physical NIC + bond + vlan 8. Physical NIC + bond + vlan + bridge Of those, the last 4 are the 'hard' ones since there are 'n' source points and 'm' end points. The end points are the core object the public API wants to deal in. The first 4 configs can all be expressed in terms of a single interface object, since there is a single end point. The last 4 configs suggest one base interface followed by 'n' additional interfaces, with the break being where the 1 -> 'n' relation appears. The idea of having the intermediate 'end point' appear as an interface object in the public API makes sense, because these can exist in their own right, before VLANs are added. Only bonds/bridges need to be defined as a single entity. So the possible configs would appear as XML like 1. Physical NIC <interface type='ethernet'> <name>eth0</name> </interface> 2. Physical NIC + bridge <interface type="bridge"> <name>br0</name> <bridge> <interface type='ethernet'> <name>eth0</name> </interface> </bridge> </interface> 3. Physical NIC + bond <interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface> 4. Physical NIC + bond + bridge <interface type="bridge"> <name>br0</name> <bridge> <interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface> </bridge> </interface> 5. Physical NIC + 2 * vlan <interface type="ethernet"> <name>eth0</name> </interface> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface> <interface type="vlan"> <name>vlan48</name> <vlan tag='48'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface> 6. Physical NIC + 2 * vlan + bridge <interface type="ethernet"> <name>eth0</name> </interface> <interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface> </bridge> </interface> <interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface> </bridge> </interface> 7. Physical NIC + bond + 2 * vlan <interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> <interface type="vlan"> <name>vlan48</name> <vlan tag='48'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> 8. Physical NIC + bond + 2 * vlan + bridge <interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface> <interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> </bridge> </interface> <interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> </bridge> </interface> Of course, you could actually have a hybrid of 7/8, where some vlans where bridged, and others direct endpoints. That's trivally handled there of course. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Fri, Jun 19, 2009 at 05:39:57PM +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 05:53:59PM +0000, David Lutterkort wrote:
On Thu, 2009-06-18 at 18:06 +0100, Daniel P. Berrange wrote:
VLANs are tricky, because you can define VLANs on a physical inteface or a bond interface, and you then may want to also add a bridge on top of a VLAN, eg take 2 physical NICs, eth0 and eth1, here are some possible combes
- One NIC for storage, another for host mgmt, and put the guests all on VLANs
eth0 -> br0 IP addr used for storage eth1 -> br1 IP addr used for host mgmt eth1.42 -> br1.42 IP addr, used to talk to guests eth1.43 -> br1.43 No IP, guest traffic only eth1.44 -> br1.44 No IP, guest traffic only
I don't think that's the right notation, don't you mean 'eth1.42 -> br2' etc. ?
Yes that was a mistake.
I think the currently approach of modelling bond, bridges and NICs makes this a little hard, particularly if the netcf API only exposes 'connections' and not interfaces, because some of these setups are not really connections, only building blocks for 'n' other connections
For that, you'd nest them where they are used, e.g. one connection to establish the base ethernet interface (that might not exist at all):
<interface type="ethernet" startmode="none"> <name>eth0</name> <mtu size="1492"/> <mac address="aa:bb:cc:dd:ee:ff"/> <dhcp peerdns="no"/> </interface>
and one for the bridge with a vlan enslaved:
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="vlan" device="eth0" tag="42"/> </bridge> </interface>
Similarly, a bond enslaved to a bridge, together with a vlan on that bond also enslaved to the bridge would look like
<interface type="bridge" startmode="onboot"> <name>br0</name> ... <bridge stp="off"> <interface type="bond"> <name>bond0</name> <bond mode="active-backup"> <interface type="ethernet"> <name>eth1</name> </interface> <interface type="ethernet"> <name>eth0</name> </interface> </bond> </interface> <interface type="vlan" device="bond0" tag="42"/> </bridge> </interface>
Here is a proposal that is a compromise between the single hierarchy, and completely flat. The break point is only introduced where VLANs appear, which is acceptable because when defining VLAns, you don't need to define the underlying inteface at the same time - it can exist in its own right ahead of time. Only nic+bond or nics+bridge or nic+bond+bridge need to be atomically defined at once.
There are 4 possible arrangements of physical NIC, bond and vlan, each of which can use a bridge. This gives 8 total configs
1. Physical NIC
2. Physical NIC + bridge
3. Physical NIC + bond
4. Physical NIC + bond + bridge
5. Physical NIC + vlan
6. Physical NIC + vlan + bridge
7. Physical NIC + bond + vlan
8. Physical NIC + bond + vlan + bridge
Of those, the last 4 are the 'hard' ones since there are 'n' source points and 'm' end points. The end points are the core object the public API wants to deal in.
The first 4 configs can all be expressed in terms of a single interface object, since there is a single end point. The last 4 configs suggest one base interface followed by 'n' additional interfaces, with the break being where the 1 -> 'n' relation appears. The idea of having the intermediate 'end point' appear as an interface object in the public API makes sense, because these can exist in their own right, before VLANs are added. Only bonds/bridges need to be defined as a single entity.
So the possible configs would appear as XML like
1. Physical NIC
<interface type='ethernet'> <name>eth0</name> </interface>
2. Physical NIC + bridge
<interface type="bridge"> <name>br0</name> <bridge> <interface type='ethernet'> <name>eth0</name> </interface> </bridge> </interface>
3. Physical NIC + bond
<interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface>
4. Physical NIC + bond + bridge
<interface type="bridge"> <name>br0</name> <bridge> <interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface> </bridge> </interface>
5. Physical NIC + 2 * vlan
<interface type="ethernet"> <name>eth0</name> </interface>
<interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
<interface type="vlan"> <name>vlan48</name> <vlan tag='48'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
6. Physical NIC + 2 * vlan + bridge
<interface type="ethernet"> <name>eth0</name> </interface>
<interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface> </bridge> </interface>
<interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface> </bridge> </interface>
7. Physical NIC + bond + 2 * vlan
<interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface>
<interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface>
<interface type="vlan"> <name>vlan48</name> <vlan tag='48'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface>
8. Physical NIC + bond + 2 * vlan + bridge
<interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface>
<interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> </bridge> </interface>
<interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> </bridge> </interface>
Of course, you could actually have a hybrid of 7/8, where some vlans where bridged, and others direct endpoints. That's trivally handled there of course.
Hum, since an XML can only have one single root, I suggest to put a wrapper around multiple definitions and if you call it <interfaces> that looks a bit like my own proposal but more recursive. I still suggest to change having name as an attribute on the <interface> tags because it allows to easilly do the ID/IDREF matching. for references. Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Fri, Jun 19, 2009 at 07:05:23PM +0200, Daniel Veillard wrote:
On Fri, Jun 19, 2009 at 05:39:57PM +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 05:53:59PM +0000, David Lutterkort wrote:
So the possible configs would appear as XML like
1. Physical NIC
<interface type='ethernet'> <name>eth0</name> </interface>
2. Physical NIC + bridge
<interface type="bridge"> <name>br0</name> <bridge> <interface type='ethernet'> <name>eth0</name> </interface> </bridge> </interface>
3. Physical NIC + bond
<interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface>
4. Physical NIC + bond + bridge
<interface type="bridge"> <name>br0</name> <bridge> <interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface> </bridge> </interface>
5. Physical NIC + 2 * vlan
<interface type="ethernet"> <name>eth0</name> </interface>
<interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
<interface type="vlan"> <name>vlan48</name> <vlan tag='48'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
6. Physical NIC + 2 * vlan + bridge
<interface type="ethernet"> <name>eth0</name> </interface>
<interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface> </bridge> </interface>
<interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface> </bridge> </interface>
7. Physical NIC + bond + 2 * vlan
<interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface>
<interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface>
<interface type="vlan"> <name>vlan48</name> <vlan tag='48'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface>
8. Physical NIC + bond + 2 * vlan + bridge
<interface type="bond"> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface>
<interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> </bridge> </interface>
<interface type='bridge'> <name>br42</name> <bridge> <interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> </bridge> </interface>
Of course, you could actually have a hybrid of 7/8, where some vlans where bridged, and others direct endpoints. That's trivally handled there of course.
Hum, since an XML can only have one single root, I suggest to put a wrapper around multiple definitions and if you call it <interfaces> that looks a bit like my own proposal but more recursive.
Sorry, I didn't explain this bit enough. In the last 4 cases where there are multiple <inteface> end-points, each of those example docs would correspond to a separate virInterfacePtr object. so there is no need for a <intefaces> wrapper around them all. eg in example 8, you would do import libvirt bondxml="<interface type='bond'> <name>bond0</name> <bond> <interface type='ethernet'> <name>eth0</name> </interface> <interface type='ethernet'> <name>eth1</name> </interface> </bond> </interface>" vlan1xml="<interface type='bridge'> <name>br42</name> <bridge> <interface type='vlan'> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> </bridge> </interface>" vlan2xml="<interface type='bridge'> <name>br42</name> <bridge> <interface type='vlan'> <name>vlan42</name> <vlan tag='42'> <interface type='bond'> <name>bond0</name> </inteface> </vlan> </inteface> </bridge> </interface>" conn = libvirt.open("xen:///") bond = conn.defineInterface(bondxml) vlan1 = conn.defineInterface(vlan1xml) vlan2 = conn.defineInterface(vlan2xml) There is no need to define all 3 at once, since it is fine for 'bond' to exist at any time before vlan1/vlan2 come along. In fact it is critical, since you will likely add/remove vlans on the fly at any time Regards, Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Fri, Jun 19, 2009 at 06:16:20PM +0100, Daniel P. Berrange wrote:
On Fri, Jun 19, 2009 at 07:05:23PM +0200, Daniel Veillard wrote:
Of course, you could actually have a hybrid of 7/8, where some vlans where bridged, and others direct endpoints. That's trivally handled there of course.
Hum, since an XML can only have one single root, I suggest to put a wrapper around multiple definitions and if you call it <interfaces> that looks a bit like my own proposal but more recursive.
Sorry, I didn't explain this bit enough. In the last 4 cases where there are multiple <inteface> end-points, each of those example docs would correspond to a separate virInterfacePtr object. so there is no need for a <intefaces> wrapper around them all. eg in example 8, you would do
There is no need to define all 3 at once, since it is fine for 'bond' to exist at any time before vlan1/vlan2 come along. In fact it is critical, since you will likely add/remove vlans on the fly at any time
A top level <interfaces> would not prevent from calling the API multiple times. But the cleanup I suggested of separating declarations of interfaces from their reuse in other blocks would make the XML regular, as in you know that <interface> at level 0 or 1 would be a definition, and the other ones would be links (which are defined in XML as ID/IDREF mechanism) http://www.w3.org/TR/REC-xml/#id http://www.w3.org/TR/REC-xml/#idref that could be trivially validated either directly by the RelaxNG in case of complete dumps. The user may be interested in getting full dumps of its network setup and not N pieces so I think the format makes sense at the API level too. An user could make a full dump of its networking setup and validate in one pass or check for more subtle construct problems. Sorry if this is a bit different from what you had in mind, it doesn't prevent your scenario, allows IMHO to clarify the XML format quite a bit and provides a format and API which can be useful to users. I will note that in general it's way easier to manipulate complete XML document than a set of fractional pieces, things like APIs and processing can be greatly simplified one concrete example being that you can just pipe one document though a file descriptor, but piping a series of document usually gets nasty. Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Fri, 2009-06-19 at 17:39 +0100, Daniel P. Berrange wrote:
Here is a proposal that is a compromise between the single hierarchy, and completely flat. The break point is only introduced where VLANs appear, which is acceptable because when defining VLAns, you don't need to define the underlying inteface at the same time
Yes, that's what I was getting at in one of my mails yesterday. All subordinate interfaces, except for VLAN's, are defined by including them at the one place where they are used (e.g., inside <bridge/>); when using a VLAN as a subordinate interface, the VLAN interface itself is defined where it is used, but the interface underlying the VLAN interface is only referred to. Basically, by treating VLAN's akin to symbolic links, we do a have a clean tree structure for interface nesting.
There are 4 possible arrangements of physical NIC, bond and vlan, each of which can use a bridge. This gives 8 total configs
1. Physical NIC
2. Physical NIC + bridge
3. Physical NIC + bond
4. Physical NIC + bond + bridge
5. Physical NIC + vlan
6. Physical NIC + vlan + bridge
7. Physical NIC + bond + vlan
8. Physical NIC + bond + vlan + bridge
Agreed - these examples are in line with what I had in mind. The format for VLAN's is a bit problematic still; you have
<interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
but you can't really assign an arbitrary name to a VLAN interface; it's also not necessary to indicate the type of the base interface. Therefore, for VLAN's, I would use the much more concise notation <interface type="vlan" device="eth0" tag="42"/> David
On Fri, Jun 19, 2009 at 05:44:25PM +0000, David Lutterkort wrote:
There are 4 possible arrangements of physical NIC, bond and vlan, each of which can use a bridge. This gives 8 total configs
1. Physical NIC
2. Physical NIC + bridge
3. Physical NIC + bond
4. Physical NIC + bond + bridge
5. Physical NIC + vlan
6. Physical NIC + vlan + bridge
7. Physical NIC + bond + vlan
8. Physical NIC + bond + vlan + bridge
Agreed - these examples are in line with what I had in mind. The format for VLAN's is a bit problematic still; you have
<interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
but you can't really assign an arbitrary name to a VLAN interface; it's also not necessary to indicate the type of the base interface. Therefore, for VLAN's, I would use the much more concise notation
<interface type="vlan" device="eth0" tag="42"/>
If you can't generally assign the VLAN name, then I think its better to make the '<name>' element optional at time of defining the interface. We still need to have a <name> element available for dumpxml and purposes of obtaining interface object handles, since that's done based on interface name. And it means applications querying the XML can rely on the interface name always being present at the top level, and for any nested <interface> elements. So rather prefer to still have the more verbose XML I describe, than the one-liner. (The nested 'type' attribute could be optional too) Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Fri, Jun 19, 2009 at 05:39:57PM +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 05:53:59PM +0000, David Lutterkort wrote: 5. Physical NIC + 2 * vlan
<interface type="ethernet"> <name>eth0</name> </interface>
<interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
<interface type="vlan"> <name>vlan48</name> <vlan tag='48'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
Does this mean 3 calls to the API ? Because as-is this is not XML obviously... Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Fri, Jun 19, 2009 at 08:19:24PM +0200, Daniel Veillard wrote:
On Fri, Jun 19, 2009 at 05:39:57PM +0100, Daniel P. Berrange wrote:
On Thu, Jun 18, 2009 at 05:53:59PM +0000, David Lutterkort wrote: 5. Physical NIC + 2 * vlan
<interface type="ethernet"> <name>eth0</name> </interface>
<interface type="vlan"> <name>vlan42</name> <vlan tag='42'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
<interface type="vlan"> <name>vlan48</name> <vlan tag='48'> <interface type='ethernet'> <name>eth0</name> </inteface> </vlan> </inteface>
Does this mean 3 calls to the API ? Because as-is this is not XML obviously...
Yes. See my python code example in my other reply.. Regards, Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, 2009-06-18 at 16:06 +0200, Daniel Veillard wrote:
On Thu, Jun 18, 2009 at 10:46:45AM +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 10:59:20PM +0000, David Lutterkort wrote:
The problem with the propsal is that it opens the door to a variety of errors like using the same familly twice, which I would like to avoid at the RNG level but it's not trivial.
An alternative is to drop the <addresses/> tag and just stick a type=ipv4|ipv6 attribute on the <ip/> tags .. though that requirs that we do the same for <route/> tags, and I have no idea what routing in non-IP protocols looks like.
We should allow standalone IPv4 and IPv6, or both. Each could either use DHCP or allow one or more IP address and routes. I think if we have routes, at most one need to be a gateway and the other ones having destination + prefix.
So I suggest the following rewrite of interface-addressing
<!-- Assignment of IP address to an interface --> <define name="interface-addressing"> <choice> <ref name="interface-addr-ipv4"/> <ref name="interface-addr-ipv6"/> <group> <ref name="interface-addr-ipv4"/> <ref name="interface-addr-ipv6"/> </group> </choice> </define>
Ok.
This allows one or 2 blocks of addresses ipv4, ipv6 or both
<define name="interface-addr-ipv4"> <element name="addresses"> <attribute name="family"> <value>ipv4</value> </attribute> <choice> <ref name="interface-addr-static"/> <ref name="interface-addr-dhcp"/> </choice> </element> </define>
An IPv4 addresses block, allows for either static or dhcp
<define name="interface-addr-ipv6"> <element name="addresses"> <attribute name="family"> <value>ipv6</value> </attribute> <choice> <ref name="interface-addr-static"/> <ref name="interface-addr-dhcp"/> </choice> </element> </define>
interface-addr-static and interface-addr-dhcp need to be split into ipv4 and ipv6 specific branches, so that we can typecheck that we don't use an ipv6 address in an ipv4 addressing block. Ultimately, that means we need ipv4 and ipv6 versions of ip-addr and prefix-pattern.
For DHCP the only option is the peerdns yes/no attribute
There's a few more options we need to add for completeness, at least PERSISTENT_DHCLIENT, DHCPRELEASE, and DHCLIENT_IGNORE_GATEWAY are supported by initscripts.
And for routes we have at least one default route
Default route should be optional.
This makes parsing a bit heavier, and I didn't checked if this really affected bridging and bonding interfaces in a wrong way, but I think that at least at an ethernet level definition this looks more complete.
It only affects it in so far as interface-addressing is also used for the toplevel bridge/bond devices, which AFAIK is ok.
That said I have no idea how much of a problem it would be on the netcf impletmentation side.
I will find out ;)
P.S.: full rng attached, double check the prefix-pattern definition I have no idea if it's sufficient for Ipv6
For ipv4, prefix is in the range 1..32, for ipv6, it's 1..128. David

On Thu, Jun 18, 2009 at 05:14:44PM +0000 David Lutterkort wrote: [..]
There's a few more options we need to add for completeness, at least PERSISTENT_DHCLIENT, DHCPRELEASE, and DHCLIENT_IGNORE_GATEWAY are supported by initscripts.
This raises a question - how should the features of some backends and the deficiencies of other backends be handled? Should netcf aim to handle just about everything? What about libvirt in the case that the netcf XML API is extended and the libvirt XML API is incompatible? What about features that are very similar but not exactly the same (an example is the SuSE STARTMODE which allows an interface to be started automatically at boot, when the if is hotplugged, from ifplugd (!= hotplugged, apparently), or autostarted but never automatically shut down)? These decisions are best done on a case-to-case-basis, but it would be nice for some general direction. As libvirt seems to be the first "customer" of netcf, this question is best raised in this forum as well. General thoughts? More examples? Regards, Jonas -- Jonas Eriksson Consultant at AS/EAB/FLJ/IL Phone: +46 8 58086281 Combitech AB Älvsjö, Sweden
On Mon, Jun 22, 2009 at 10:58:49AM +0200, Jonas Eriksson wrote:
On Thu, Jun 18, 2009 at 05:14:44PM +0000 David Lutterkort wrote: [..]
There's a few more options we need to add for completeness, at least PERSISTENT_DHCLIENT, DHCPRELEASE, and DHCLIENT_IGNORE_GATEWAY are supported by initscripts.
This raises a question - how should the features of some backends and the deficiencies of other backends be handled? Should netcf aim to handle just about everything? What about libvirt in the case that the netcf XML API is extended and the libvirt XML API is incompatible? What about features that are very similar but not exactly the same (an example is the SuSE STARTMODE which allows an interface to be started automatically at boot, when the if is hotplugged, from ifplugd (!= hotplugged, apparently), or autostarted but never automatically shut down)?
libvirt does not require that all functionality is present on all platforms. So as long as an error is raised if the user requests an unsupported configuration, we're fine. As for the XML question, libvirt requires 100% backwards compatability so its XML format is essentially "append" only, existing features cannot be dropped/changed. libvirt will be parsing & reformatting all XML coming to/from netcf to guarentee that it is compliant with libvirt's advertised schema (even if this happens to be the same as netcf's) Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Mon, 2009-06-22 at 10:50 +0100, Daniel P. Berrange wrote:
libvirt does not require that all functionality is present on all platforms. So as long as an error is raised if the user requests an unsupported configuration, we're fine. As for the XML question, libvirt requires 100% backwards compatability so its XML format is essentially "append" only, existing features cannot be dropped/changed.
This is also the intent for netcf's XML (warning: neither the XML format nor the API can be considered stable yet, but I hope that we get to that point very soon) As for backend differences, we definitely need to address them on a case-by-case basis, weighing the headache of dealing with different backends with different feature sets against the importance of that feature. David
On Thu, 2009-06-18 at 10:46 +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 10:59:20PM +0000, David Lutterkort wrote:
On Wed, 2009-06-17 at 21:32 +0100, Daniel P. Berrange wrote:
How do you deal with IPv6 currently ?
With lots of Aspirin (actually, not at all)
I was thinking of sugesting an attribute
<ip type="ipv6" address="2001:23::2" prefix="24"/>
but I think its possibly better to have a different element name
<ip6 address="2001:23::2" prefix="24"/>
since the former would not work if we ever needed to worry about non-IP based addresses.
Either works for me, with a slight preference for the first version, on purely esthetic grounds. And even if we go with that, there's nothing keeping us from adding an <ipx> element as an alternative to the <ip> element in the future.
Or a 3rd option is to group addresses by family
<addresses family='ipv4'> <ip address='122.0.0.3' prefix='24'/> <ip address='24.24.224.4' prefix='24'/> </addresses> <addresses family='ipv6'> <ip address='2001:23::2' prefix='48'/> <ip address='fe:33:55::33' prefix='64'/> </addresses> <adddresses family='ipx'> <ipx address='2423.4521.66.3.252.'/> </address>
I don't see that that buys us anything that we wouldn't have with <ip type='ipv4' address='122.0.0.3' prefix='24'/> <ip type='ipv4' address='24.24.224.4' prefix='24'/> <ip type='ipv6' address='2001:23::2' prefix='48'/> <ip type='ipv6' address='fe:33:55::33' prefix='64'/> <ipx address='2423.4521.66.3.252.'/> _maybe_ enclosed in a <addresses> container tag, but I don't think that's needed. David
On Thu, Jun 18, 2009 at 09:42:40AM -0700, David Lutterkort wrote:
On Thu, 2009-06-18 at 10:46 +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 10:59:20PM +0000, David Lutterkort wrote:
On Wed, 2009-06-17 at 21:32 +0100, Daniel P. Berrange wrote:
How do you deal with IPv6 currently ?
With lots of Aspirin (actually, not at all)
I was thinking of sugesting an attribute
<ip type="ipv6" address="2001:23::2" prefix="24"/>
but I think its possibly better to have a different element name
<ip6 address="2001:23::2" prefix="24"/>
since the former would not work if we ever needed to worry about non-IP based addresses.
Either works for me, with a slight preference for the first version, on purely esthetic grounds. And even if we go with that, there's nothing keeping us from adding an <ipx> element as an alternative to the <ip> element in the future.
Or a 3rd option is to group addresses by family
<addresses family='ipv4'> <ip address='122.0.0.3' prefix='24'/> <ip address='24.24.224.4' prefix='24'/> </addresses> <addresses family='ipv6'> <ip address='2001:23::2' prefix='48'/> <ip address='fe:33:55::33' prefix='64'/> </addresses> <adddresses family='ipx'> <ipx address='2423.4521.66.3.252.'/> </address>
I don't see that that buys us anything that we wouldn't have with
<ip type='ipv4' address='122.0.0.3' prefix='24'/> <ip type='ipv4' address='24.24.224.4' prefix='24'/> <ip type='ipv6' address='2001:23::2' prefix='48'/> <ip type='ipv6' address='fe:33:55::33' prefix='64'/> <ipx address='2423.4521.66.3.252.'/>
If you do this, then you'll need an explicit element to turn on / off IPv4 or IPv6 addressing for the inteface as whole. ie to stop the automatic addition of a link-local address. By having the container, for each family, the prescense or not of the container can define whether that address family is enabled for that inteface. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, 2009-06-18 at 18:10 +0100, Daniel P. Berrange wrote:
I don't see that that buys us anything that we wouldn't have with
<ip type='ipv4' address='122.0.0.3' prefix='24'/> <ip type='ipv4' address='24.24.224.4' prefix='24'/> <ip type='ipv6' address='2001:23::2' prefix='48'/> <ip type='ipv6' address='fe:33:55::33' prefix='64'/> <ipx address='2423.4521.66.3.252.'/>
If you do this, then you'll need an explicit element to turn on / off IPv4 or IPv6 addressing for the inteface as whole. ie to stop the automatic addition of a link-local address.
That should be stated explicitly, not implied by having an empty <address/> tag.
By having the container, for each family, the prescense or not of the container can define whether that address family is enabled for that inteface.
What would 'enabling an address family for an interface' do ? Whatever it does should probably be stated explicitly. The one argument for <address> tags is that it makes it cleaner to bundle addressing info like <ip> and routing info, to make sure that the user doesn't specify ipv6 routes for an interface without ipv6 addresses. David
On Thu, Jun 18, 2009 at 10:56:44PM +0000, David Lutterkort wrote:
The one argument for <address> tags is that it makes it cleaner to bundle addressing info like <ip> and routing info, to make sure that the user doesn't specify ipv6 routes for an interface without ipv6 addresses.
Yes that grouping is what I really had in mind when I did the exercise in modelling based on Dan's version. I would say that from an human POV it also immediately make clear what IP versions are supported, easier to look at the attriubutes on teh big blocks and the number of big blocks. I think it makes it a bit less error-prone. Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Thu, Jun 18, 2009 at 10:56:44PM +0000, David Lutterkort wrote:
On Thu, 2009-06-18 at 18:10 +0100, Daniel P. Berrange wrote:
I don't see that that buys us anything that we wouldn't have with
<ip type='ipv4' address='122.0.0.3' prefix='24'/> <ip type='ipv4' address='24.24.224.4' prefix='24'/> <ip type='ipv6' address='2001:23::2' prefix='48'/> <ip type='ipv6' address='fe:33:55::33' prefix='64'/> <ipx address='2423.4521.66.3.252.'/>
If you do this, then you'll need an explicit element to turn on / off IPv4 or IPv6 addressing for the inteface as whole. ie to stop the automatic addition of a link-local address.
That should be stated explicitly, not implied by having an empty <address/> tag.
IMHO that results in a bad structure, because its anot associating the related info together, eg having an separate element to turn on/off IPV6, and then listing addresses: <address family='ipv6'/> <ip type='ipv6' address='2001:23::2' prefix='48'/> <ip type='ipv6' address='fe:33:55::33' prefix='64'/> vs having the direct association <address family='ipv6'> <ip address='2001:23::2' prefix='48'/> <ip address='fe:33:55::33' prefix='64'/> </address> the latter removes the redundancy from specifying address family in multiple places
By having the container, for each family, the prescense or not of the container can define whether that address family is enabled for that inteface.
What would 'enabling an address family for an interface' do ? Whatever it does should probably be stated explicitly.
That's really protocol specific, but it will typically enable some local address auto-config by the kernel. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Fri, 2009-06-19 at 10:47 +0100, Daniel P. Berrange wrote:
IMHO that results in a bad structure, because its anot associating the related info together, eg having an separate element to turn on/off IPV6, and then listing addresses:
<address family='ipv6'/> <ip type='ipv6' address='2001:23::2' prefix='48'/> <ip type='ipv6' address='fe:33:55::33' prefix='64'/>
vs having the direct association
<address family='ipv6'> <ip address='2001:23::2' prefix='48'/> <ip address='fe:33:55::33' prefix='64'/> </address>
the latter removes the redundancy from specifying address family in multiple places
Ok .. I agree that we should have a container tag like that - we should probably call it <protocol/> though instead of <address/> <protocol family='ipv6'> <ip .../> <route .../> ... other ipv6 specific settings ... </protocol> David
On Fri, Jun 19, 2009 at 05:47:44PM +0000, David Lutterkort wrote:
On Fri, 2009-06-19 at 10:47 +0100, Daniel P. Berrange wrote:
IMHO that results in a bad structure, because its anot associating the related info together, eg having an separate element to turn on/off IPV6, and then listing addresses:
<address family='ipv6'/> <ip type='ipv6' address='2001:23::2' prefix='48'/> <ip type='ipv6' address='fe:33:55::33' prefix='64'/>
vs having the direct association
<address family='ipv6'> <ip address='2001:23::2' prefix='48'/> <ip address='fe:33:55::33' prefix='64'/> </address>
the latter removes the redundancy from specifying address family in multiple places
Ok .. I agree that we should have a container tag like that - we should probably call it <protocol/> though instead of <address/>
<protocol family='ipv6'> <ip .../> <route .../> ... other ipv6 specific settings ... </protocol>
That naming works for me Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Wed, Jun 17, 2009 at 01:27:14PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 22:10 +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 09:03:32PM +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 09:42:11PM +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 12:22:13PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote:
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured.
BTW I was looking at the Relax-NG grammar and found the following confusing when providing an IP address:
<element name="ip"> <optional> <attribute name="address"><ref name="ip-mask"/></attribute> </optional> </element>
I'm not really sure what ip-mask really means, are you trying to put in a single attribute both the IP address and the netmask ? If that's the case I would really suggest to split the two as separated IP and netmask in the XML structure, either separate attributes or another element for the netmask. Best to us the explicit structure of XML than a construct hidden inside the text field, unless I misunderstood the use case...
'netmask' should really be avoided these days, in preference to 'prefix' since the latter works for IPv4 and IPv6, while the former only works for IPv4. 'netmask' can be auto-calculated from 'prefix' by apps if they really care about it.
Fine by me, just that I think they should be hold by 2 separate attributes or element if possible at this point.
Yes, good point; and I don't know what I was thinking when I made the address attribute optional.
I'll change the schema to this:
<element name="ip"> <attribute name="address"><ref name="ip-addr"/></attribute> <attribute name="prefix"><ref name="prefix-pattern"/></attribute> </element>
so that you'll write
<ip address="172.32.12.10" prefix="24"/>
Cool :-)
I haven't declared the schema or the API stable yet, but I want to do that once there is a libvirt release out there that relies on netcf. So if there are any other issues with any of these aspects, raise them now or forever hold your peace.
Well I'm writing the parser, so sure I will raise those :-) There is also a lot of suggested extensions from Jim Fehlig, but I think they all can be handled as extension from the original schemas. One thing which needs to be ironed out IMHO is IPv6, better clean this up now than later. I'm not a IPv6 fan but making sure the schemas is ready for it is important I guess. The comment about <dhcp6 /> should probably be decided before first release. Daniel -- Daniel Veillard | libxml Gnome XML XSLT toolkit http://xmlsoft.org/ daniel@veillard.com | Rpmfind RPM search engine http://rpmfind.net/ http://veillard.com/ | virtualization library http://libvirt.org/
On Wed, Jun 17, 2009 at 10:33:02PM +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 01:27:14PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 22:10 +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 09:03:32PM +0100, Daniel P. Berrange wrote:
On Wed, Jun 17, 2009 at 09:42:11PM +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 12:22:13PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote: > IP address information should be in the XML, and indeed surely it is > already there in order to allow non-DHCP based IP address config > on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured.
BTW I was looking at the Relax-NG grammar and found the following confusing when providing an IP address:
<element name="ip"> <optional> <attribute name="address"><ref name="ip-mask"/></attribute> </optional> </element>
I'm not really sure what ip-mask really means, are you trying to put in a single attribute both the IP address and the netmask ? If that's the case I would really suggest to split the two as separated IP and netmask in the XML structure, either separate attributes or another element for the netmask. Best to us the explicit structure of XML than a construct hidden inside the text field, unless I misunderstood the use case...
'netmask' should really be avoided these days, in preference to 'prefix' since the latter works for IPv4 and IPv6, while the former only works for IPv4. 'netmask' can be auto-calculated from 'prefix' by apps if they really care about it.
Fine by me, just that I think they should be hold by 2 separate attributes or element if possible at this point.
Yes, good point; and I don't know what I was thinking when I made the address attribute optional.
I'll change the schema to this:
<element name="ip"> <attribute name="address"><ref name="ip-addr"/></attribute> <attribute name="prefix"><ref name="prefix-pattern"/></attribute> </element>
so that you'll write
<ip address="172.32.12.10" prefix="24"/>
Cool :-)
I haven't declared the schema or the API stable yet, but I want to do that once there is a libvirt release out there that relies on netcf. So if there are any other issues with any of these aspects, raise them now or forever hold your peace.
Well I'm writing the parser, so sure I will raise those :-)
There is also a lot of suggested extensions from Jim Fehlig, but I think they all can be handled as extension from the original schemas. One thing which needs to be ironed out IMHO is IPv6, better clean this up now than later. I'm not a IPv6 fan but making sure the schemas is ready for it is important I guess. The comment about <dhcp6 /> should probably be decided before first release.
Yeah we definitely need IPv6 stuff in the first of this since RHEL-5 and later are required to support IPv6 for every network service, and I'm sure other enterprise distros have a similar requirement Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Wed, 2009-06-17 at 22:33 +0200, Daniel Veillard wrote:
On Wed, Jun 17, 2009 at 01:27:14PM -0700, David Lutterkort wrote:
I haven't declared the schema or the API stable yet, but I want to do that once there is a libvirt release out there that relies on netcf. So if there are any other issues with any of these aspects, raise them now or forever hold your peace.
Well I'm writing the parser, so sure I will raise those :-)
There is also a lot of suggested extensions from Jim Fehlig, but I think they all can be handled as extension from the original schemas. One thing which needs to be ironed out IMHO is IPv6, better clean this up now than later. I'm not a IPv6 fan but making sure the schemas is ready for it is important I guess. The comment about <dhcp6 /> should probably be decided before first release.
The most important thing is that we do not need to break the schema in an incompatible way. Extensions can always be added later. David
On Wed, Jun 17, 2009 at 01:27:14PM -0700 David Lutterkort wrote:
or forever hold your peace.
While talking about the relax-ng schema, I would like to again raise my question earlier raised at the netcf-devel-list in order to get some input from the libvirt developers on this matter as well. I am a bit critical to the policy restrictions of the current incarnation of the netcf API. Currently, a interface (or connection) has to have an IP address and a bridge has to have one or more interfaces attached to it. Not having the IP address restriction may collide head on with the connection-approach for some, as a connection probably have to be addressable. I however argue that this severly limits the uses for netcf, say for example to only bridge two interfaces without caring (and perhaps not wanting) to be something other then a package forwarder and not care about IP-address collisions. And in another case, the addressing is done using something other then IP. For the bridges without added interfaces, an example is libvirt that have these private networks that I don't think I have to go in to in detail. My strongest point in both cases is that both restrictions is policy-driven. If for example an option in a configuration file for an interface is not recognized by netcf, it may be simply ignored and later merged back in to the configuration if this is updated through netcf. The restrictions in IP-addresses and bridge members can however make an existing configuration clash with netcf. In the end, there is nothing that stops end applications to implement this policy if required. As said, I raised this question on netcf-devel, and David and I have been having some back-and-forth about this [1]. I also promised to raise this question here as per request about a month ago. What are the views of the libvirt community? Is netcf planned to be used for the "isolated" libvirt-networks? Will there be a case where a forwarding bridge perferably would lack an IP address? Other thoughts? Best regards, Jonas [1] https://fedorahosted.org/pipermail/netcf-devel/2009-May/thread.html https://fedorahosted.org/pipermail/netcf-devel/2009-June/000012.html https://fedorahosted.org/pipermail/netcf-devel/2009-June/000013.html -- Jonas Eriksson Consultant at AS/EAB/FLJ/IL Combitech AB Dlvsjv, Sweden
On Thu, Jun 18, 2009 at 09:15:54AM +0200, Jonas Eriksson wrote:
On Wed, Jun 17, 2009 at 01:27:14PM -0700 David Lutterkort wrote:
or forever hold your peace.
While talking about the relax-ng schema, I would like to again raise my question earlier raised at the netcf-devel-list in order to get some input from the libvirt developers on this matter as well.
I am a bit critical to the policy restrictions of the current incarnation of the netcf API. Currently, a interface (or connection) has to have an IP address and a bridge has to have one or more interfaces attached to it.
Not having the IP address restriction may collide head on with the connection-approach for some, as a connection probably have to be addressable. I however argue that this severly limits the uses for netcf, say for example to only bridge two interfaces without caring (and perhaps not wanting) to be something other then a package forwarder and not care about IP-address collisions. And in another case, the addressing is done using something other then IP.
Indeed having a bridge without an IP address is an important feature for virtualization, because you may wish to have the host completely separate from guests in terms of IP subnets. Thus you would not want the bridge to have an IP address to which the guest can connect. So IP must be optional, allowing for a choice of 'none', 'manual' or 'dhcp', or in IPv6 case 'none', 'manual', 'autoconf', or 'dhcp'.
For the bridges without added interfaces, an example is libvirt that have these private networks that I don't think I have to go in to in detail.
Actually the libvirt private networks should not be visible via this virInterface/netcf API IMHO. I agree with your point though, that it may be desirable to create bridges without any interface attached. Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
On Thu, 2009-06-18 at 09:15 +0200, Jonas Eriksson wrote:
I am a bit critical to the policy restrictions of the current incarnation of the netcf API. Currently, a interface (or connection) has to have an IP address and a bridge has to have one or more interfaces attached to it.
Ok .. I relent ;) You and Dan have convinced me that those restrictions are bunk, and I'll change things to remove them - though patches that do that would be much appreciated. David
On Thu, Jun 18, 2009 at 11:02:03PM +0000 David Lutterkort wrote:
On Thu, 2009-06-18 at 09:15 +0200, Jonas Eriksson wrote:
I am a bit critical to the policy restrictions of the current incarnation of the netcf API. Currently, a interface (or connection) has to have an IP address and a bridge has to have one or more interfaces attached to it.
Ok .. I relent ;) You and Dan have convinced me that those restrictions are bunk, and I'll change things to remove them - though patches that do that would be much appreciated.
You mean I won an argument on the internet? ;) I will try to make time to check the drv_initscript.c +(.xsl) as well.. I'm currently working on a SuSE-driver and have no Red Hat machine to try stuff on, although it ought to be simple to see that things works as intended anyway. Regards, Jonas -- Jonas Eriksson Consultant at AS/EAB/FLJ/IL Phone: +46 8 58086281 Combitech AB Älvsjö, Sweden
On Wed, Jun 17, 2009 at 12:22:13PM -0700, David Lutterkort wrote:
On Wed, 2009-06-17 at 19:24 +0100, Daniel P. Berrange wrote:
IP address information should be in the XML, and indeed surely it is already there in order to allow non-DHCP based IP address config on interfaces ?
Yes, for statically configured interfaces, the IP information is in the XML - that is the _configured_ IP info though, not necessarily the one that the interface actually uses. The two can diverge, for example, if an interface is already up and then reconfigured.
We should be using a flag for virInterfaceDumpXML to deal with this problem, eg virInterfaceDumpXML(iface, 0) would give the config appropriate to the device's current state. To explicitly get the inactive config for a interface that is active, you would then do virInterfaceDumpXML(iface, VIR_INTERFACE_INACTIVE). This matches what we do for guest domain XML, eg to cope with VNC port number auto-allocation, or PTY device naming auto-allocation So, even if the XML indicates type=dhcp, then for an active interface you'd still expect to get back multiple IP address elements for each configured address Regards, Daniel -- |: Red Hat, Engineering, London -o- http://people.redhat.com/berrange/ :| |: http://libvirt.org -o- http://virt-manager.org -o- http://ovirt.org :| |: http://autobuild.org -o- http://search.cpan.org/~danberr/ :| |: GnuPG: 7D3B9505 -o- F3C9 553F A1DA 4AC2 5648 23C1 B3DF F742 7D3B 9505 :|
participants (5)
-
 Daniel P. Berrange
Daniel P. Berrange -
 Daniel Veillard
Daniel Veillard -
 David Lutterkort
David Lutterkort -
 Jonas Eriksson
Jonas Eriksson -
 Laine Stump
Laine Stump